Vom Datengrab zum Datenschatz: MQTT, InfluxDB, und Grafana zum Aus- und Aufwerten deiner IoT-Daten


In diesem ersten Teil der Serie beschäftigen wir uns primär mit der Speicherung von Sensordaten, die in deinem Smarthome anfallen. Das erlaubt später Auswertungen und gegebenenfalls Strategien zum Energie-Sparen zu entwickeln. Denn keine Optimierung sollte ohne Anlass in Form von Daten passieren und der erste Schritt zur Datenauswertung ist es, die Daten erst einmal zu speichern.
Insgesamt beschäftigen wir uns in dieser mehrteiligen Serie mit drei Infrastrukturthemen: 1. Datenspeicherung, 2. Datenvisualisierung und 3. Datenauswertung. Die Installationen dafür basieren auf dem treuen Raspberry Pi, der uns seit dem zweiten MQTT Blogpost begleitet. Dementsprechend ist auch alles lokal und nicht bei einem Drittanbieter gehostet. Im Rahmen der Serie sprechen wir über InfluxDB, Telegraf, Grafana und voraussichtlich ein paar Python-Bibliotheken. In alle diese Technologien kannst du dich viel tiefer einarbeiten, als ich es hier zeige, es geht hier nur um einen Überblick, um einen einfachen und glatten Start hinzubekommen.
Lernziele: InfluxDB Setup, Telegraf Setup
Dauer: 1-3 Stunden
Voraussetzungen
- Installierter Raspberry Pi mit SSH Zugang und Installations-Rechten
- Installierter Mosquitto Broker auf dem Pi
- Mindestens ein IoT-Sensor der regelmäßig (zum Testen idealerweise im 1-10 Sekundentakt) Daten an den Broker schickt (im Rahmen dieses Blogposts gehe ich von einem DHT22 Temperatur- und Luftfeuchtesensor aus)
Falls etwas fehlt, zum Nachlesen: Mosquitto Installation, Mosquitto TLS Einrichtung, DHT22 Installation
Installation von InfluxDB
Da der Raspberry Pi 4 eine 64Bit ARM Prozessorarchitektur hat, musst du zuerst für die Paketverwaltung das Repository für InfluxDB hinzufügen. Stelle sicher, dass du per SSH auf dem Pi eingeloggt bist und Root-User bist*, bzw. auf dem Pi ein Root-Terminal geöffnet hast. Auf der offiziellen Downloadseite, wenn du im Dropdown Ubuntu&Debian ARM 64-Bit auswählst, findest du drei Zeilen, die du ausführst, damit die InfluxDB Paketquelle zur Installation registriert ist.
Zum Zeitpunkt des Blogposts sind es für Version 2.7.1 folgende Zeilen:
wget -q https://repos.influxdata.com/influxdata-archive_compat.key
echo '393e8779c89ac8d958f81f942f9ad7fb82a25e133faddaf92e15b16e6ac9ce4c influxdata-archive_compat.key' | sha256sum -c && cat influxdata-archive_compat.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg > /dev/null
echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg] https://repos.influxdata.com/debian stable main' | sudo tee /etc/apt/sources.list.d/influxdata.list
Zum Installieren von InfluxDB musst du dann die folgenden zwei Befehle ausführen und die Installation bestätigen:
apt update
apt install influxdb2
* um Root zu werden, kannst du zum Beispiel sudo su eintippen
Damit ist die Installation formell abgeschlossen. Was die Installation alles beinhaltet:
- InfluxDB 2.7.1 ist installiert
- Ein Systemd-Service wurde aktiviert, damit InfluxDB auch bei jedem Systemneustart mit startet
- InfluxDB wurde gestartet und ist unter Port 8086 erreichbar.
Für den nächsten Schritt geht es also weiter, damit das Webfrontend aufzurufen. Mein Raspberry Pi hat den Hostname cyberhome und ist daher von modernen Systemen unter http://cyberhome.local erreichbar. Dementsprechend ist die InfluxDB-Installation unter http://cyberhome.local:8086 erreichbar. Falls das für dich nicht funktioniert, kannst du auch die IP-Adresse des Pis verwenden, in diesem Post verwende ich immer als Beispiel: http://10.0.0.5:8086
Falls aus irgendeinem Grund der Service nicht laufen sollte, kannst du das mit dem Befehl systemctl start influxdb starten und den Autostart mit systemctl enable influxdb aktivieren. Du kannst das Start-Kommando auch problemlos nutzen, wenn der Service läuft, es macht nichts kaputt, sondern tut dann einfach nichts.
Konfiguration von InfluxDB
Wenn du die o.g. Seite das erste Mal betrittst, wirst du nach einem Klick auf "Get Started" nach einem Benutzernamen und einem Passwort gefragt. Dieser Benutzer hat dann Admin-Rechte, sollte also je nach Umgebung durchaus sicher gewählt werden. Außerdem musst du eine Organisation und einen Bucket-Namen angeben. Ich gehe nachher nochmal detaillierter auf die Bedeutung ein, für den Moment trage bei der Organisation irgendetwas ein (Ich habe für diesen Post "Plantprogrammer" gewählt) und für den Bucketnamen einen übergreifenden Projektnamen für die Daten, mit denen du arbeiten möchtest (Ich habe für diesen Post "Smarthome" gewählt).
Du bekommst, wenn das geklappt hat einen Operator-API-Token. Das ist ein Token, mit dem du dich für Admin-Aufgaben authentifizieren kannst, wenn du andere Tools als diese Website nutzt. Wir werden diesen Token nicht weiter verwenden, aber du solltest ihn sicher aufbewahren, falls du später andere Tools ausprobieren möchtest.
Konzepte hinter InfluxDB (TL;DR am Ende des Abschnitts)
InfluxDB ist für eine Großzahl sich schnell ändernder Daten gedacht, von denen man in der Regel nur ein gewisses Zeitfenster erhalten möchte. Das heißt alle Aufräumarbeiten um "alte" Daten loszuwerden, sind in der Datenbank bereits mitgedacht. Außerdem dreht sich alles um Zeitreihenbasierte Daten (Influx ist eine TSDB: Time Series DataBase). Es wird also zu jedem Datenpunkt immer ein Zeitstempel erwartet, der entweder vom Sensor mitgegeben wird oder von der Datenbank bei Empfang der Daten gesetzt wird. In InfluxDB werden Daten durch Buckets, Measurements, Tags und Fields bestimmt.
Bucket: Das ist so etwas wie eine Sub-Datenbank, die eine bestimmte Kategorie Messungen gruppiert. Im Home-Bereich wird es wahrscheinlich nicht über einen Bucket hinausgehen. Es sei denn du möchtest für Berechtigungs-Rollen verschiedenen Parteien verschiedene Messdaten zur Verfügung stellen, die dann jeweils im eigenen Bucket leben. Keine Ahnung, wenn man ein 6-Parteien Haus mit zentraler Sensorik bestückt, könnte man jeder Partei Zugriff auf die eigenen Daten geben, aber wenn man das macht, steht in DE eh sofort die Datenschutzbeauftragte auf der Matte.
Beim Anlegen eines Buckets wirst du noch gefragt, wie lange die Daten aufbewahrt werden sollen, wenn du also einen Überblick über deinen monatlichen Temperaturverlauf haben möchtest, bietet sich ein Zeitraum zwischen 1 und 2 Jahren an. Entsprechend sollte dann die Messfrequenz nicht ein mal pro Sekunde sein, sondern eher sowas wie alle 5-10 Minuten*. Wenn dich interessiert, zu welchen Tageszeiten es üblicherweise wie warm ist (oder wie viel Strom eine Steckdose verbraucht) lohnt sich ein Zeitraum von 4-8 Wochen mit einer Messfrequenz von 10-60 Sekunden**. Je nachdem was dein Anwendungsfall ist, kannst du dann bei "Delete Data" einmal auf "Older Than" klicken und dann entweder einen vorgegebenen Zeitraum auswählen oder unter "Custom Duration" einstellen.
* 1 Jahr alle 5 Minuten gemessen entspricht ca. 100.000 Messungen (365*24*60/5 = 105.120) je Messwert
** Alle 10 Sekunden messen entspricht ca. 500.000 Messungen in 8 Wochen (8*7*24*60*60/10 = 483.840) je Messwert
Measurement: Eine Messung ist wie ein Datenstrom, der eine bestimmte Art von Ereignis oder Metrik repräsentiert. Jede Messung hat immer einen Zeitstempel und einen Wert und kann mit zusätzlich mit Tags versehen werden. In unserem Beispiel wird die Temperatur eine Messung sein und die Luftfeuchtigkeit auch eine Messung.
Tags: Das sind Metadaten, die den Messpunkt näher beschreiben und später beim Sortieren, Filtern und Aggregieren helfen. Im Beispiel kannst du Tags wie "SensorID", "Standort" oder "Gerätetyp" hinzufügen, um dem eigentlichen Messwert einen Kontext zu geben.
Fields: Felder enthalten die eigentlichen Messwerte, wie Temperatur, Luftfeuchtigkeit oder wenn du smarte Steckdosen benutzt Stromstärke bzw. -verbrauch. Du kannst mehrere Felder in einer Messung haben und sie für verschiedene Arten von Messwerten verwenden. In unserem Beispiel konfiguriere ich eine Messung für Temperatur und eine für Luftfeuchtigkeit, damit ich zwei verschiedene Messungen zeigen kann und weil die Werte separat per MQTT verschickt werden. Man könnte aber auch beide (da sie von einem Sensor stammen) gemeinsam in eine Messung speichern.
Die Faustregel für Tags und Fields lautet: Oft wiederkehrende Werte, die Kategorien und keine Messwerte sind, sind Tags und stark veränderliche Werte (in erster Linie Messwerte) sind Fields.
TL;DR: InfluxDB nutzt als Tabellenbeschreibung die Einheit Measurement als Schema für die Daten. Ein Measurement besteht immer aus einem Zeitstempel und einem oder mehreren Fields die Messwerte enthalten. Zusätzlich und optional können Tags als Metadaten angegeben werden (z.B. Standort, Gerätetyp, Datenquelle). Ein Bucket ist eine Sammlung verschiedener Measurement-Definitionen.
Das war jetzt sehr viel Theorie, wenn du bis hierhin alles gelesen hast, mach mal 5 Minuten Pause bevor es weitergeht.
Zurück? Prima, dann geht es jetzt um die Frage:
Woher kommen die Daten? (Telegraf Installation)
In InfluxDB gibt es eine Millionen (dramatische Übertreibung des Autors) Möglichkeiten Datenquellen an die Datenbank anzubinden. Da die Datenquelle ein MQTT-Gerät ist, musst du diese Daten irgendwie entgegennehmen und an die Datenbank weiterreichen. Dafür kannst du deine eigenen Skripte programmieren (und ein Blogpost wie das mit Python geht wird voraussichtlich Teil dieser Serie), InfluxDB kommt aber mit einem sehr nützlichen Helfertool namens Telegraf. Technisch gesehen ist es eine separate Software, deshalb musst du sie separat installieren, die Firma, die es entwickelt, ist aber dieselbe. Los geht's wie bei InfluxDB auch mit dem Hinzufügen der Paketquelle und der Installation von telegraf. Auf der Downloadseite auch wieder Ubuntu&Debian ausgewählt und schon gibt es den folgenden Code zum Ausführen auf dem Pi:
# Hinzufügen der Paketquelle
wget -q https://repos.influxdata.com/influxdata-archive_compat.key
echo '393e8779c89ac8d958f81f942f9ad7fb82a25e133faddaf92e15b16e6ac9ce4c influxdata-archive_compat.key' | sha256sum -c && cat influxdata-archive_compat.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg > /dev/null
echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg] https://repos.influxdata.com/debian stable main' | sudo tee /etc/apt/sources.list.d/influxdata.list
# Laden der Pakete und Installation von telegraf
sudo apt update
sudo apt install telegraf
Was genau ist eigentlich telegraf?
Telegraf ist so eine Art Kommunikationsschnittstelle zwischen deinen Input-Ebene (hier z.B. Messwerte) und deiner Output-Ebene (hier die InfluxDB). Ganz plump könnte man es auch als Datenformatierungs-Werkzeug bezeichnen. Grundsätzlich kann es für verschiedene Kombinationen von Input- und Output-Schicht konfiguriert werden. Und das ist auch der Grund, warum wir es hier nutzen, weil es nur konfiguriert und nicht programmiert werden muss und mit einer Vielzahl von Formaten umgehen kann.
Wie konfiguriere ich Telegraf?
Auf dem Raspberry Pi im Verzeichnis /etc/telegraf/telegraf.d/ kannst du Dateien mit der Endung .conf ablegen, die dann automatisch als Konfiguration verwendet werden. Das ist besonders dann hilfreich, wenn du viele verschiedene Konfigurationen nutzen möchtest. Telegraf hat aber noch eine andere coole Möglichkeit, es kann die Konfiguration von einer URL laden. Jetzt kommt leider auch ein Wermutsstropfen, es ist meines Wissens nicht möglich, eine .conf Datei anzulegen, die nur auf eine URL zeigt, von der die eigentliche Konfiguration geladen werden muss. Deshalb wird das aktivieren der Konfiguration etwas umständlicher. Die gute Nachricht hingegen ist, dass InfluxDB eine gute Basiskonfiguration erstellen kann und eine solche URL zur Verfügung stellt, sodass du, wenn es einmal eingerichtet ist, bei Änderungen nur die InfluxDB Webseite benötigst.
Konfiguration erstellen
Diese Aufgabe übernimmt zu 80% InfluxDB für dich. Gehe also im Browser auf http://10.0.0.5:8086/ und logge dich mit deinem Benutzer und Passwort ein, falls nicht schon geschehen. In der Menüleiste links gibt es den Eintrag "Load Data->Sources" (Pfeil-Icon), der dich zur Übersicht deiner Datenquellen bringt. Dort kannst du eine neue Datenquelle hinzufügen. Scrolle herunter zum Abschnitt Telegraf Plugins und suche nach "MQTT consumer". Klicke auf dieses Icon und auf der Seite die aufgeht auf "Use this Plugin" -> "Create new Configuration". Du wirst jetzt nach einem Namen für die Config gefragt. Ich habe mich für "DataCollector" entschieden, es kann aber jederzeit geändert werden. Wähle noch Smarthome als Bucket aus.
In der Config, die dann geöffnet wird musst du ein paar Eintragungen machen, um zu definieren, wie deine Daten interpretiert werden müssen.
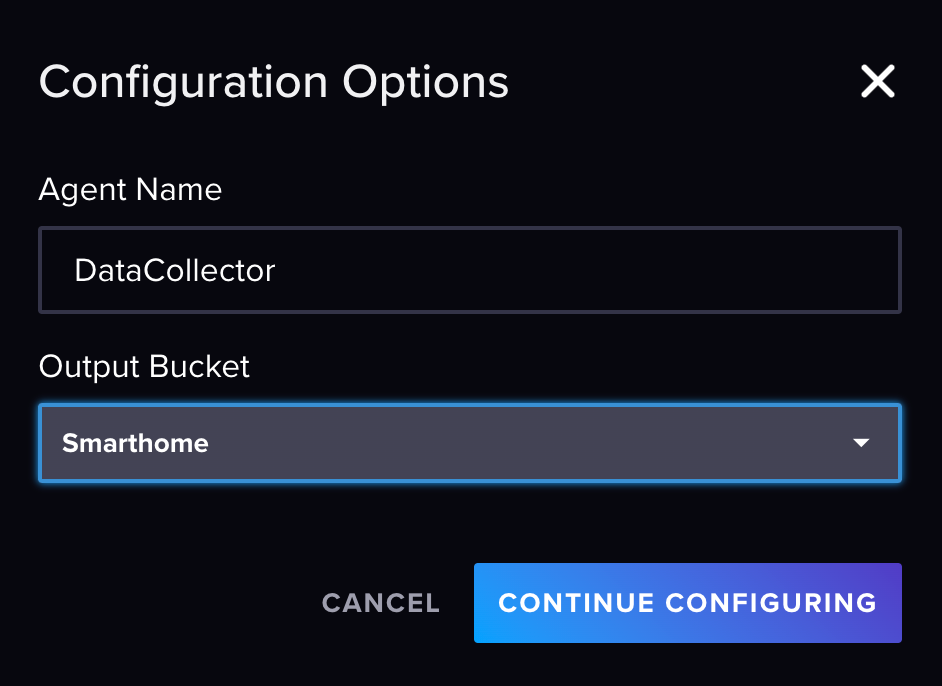
Minimale Beispielkonfiguration für DHT22-Daten
Die Daten werden auf den folgenden Topics veröffentlicht:
- sensors/<ort>/temp
- sensors/<ort>/humi
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
hostname = ""
omit_hostname = false
[[outputs.influxdb_v2]]
urls = ["http://localhost:8086"]
token = "$INFLUX_TOKEN"
organization = "Plantprogrammer"
bucket = "Smarthome"
[[inputs.mqtt_consumer]]
servers = ["tcp://127.0.0.1:1883"]
# username = "telegraf"
# password = "metricsmetricsmetricsmetrics"
topics = [
"sensors/#",
]
data_format = "value"
data_type = "float"
[[inputs.mqtt_consumer.topic_parsing]]
topic = "sensors/+/+"
measurement = "_/_/measurement"
tags = "_/device/_"
Die meisten Zeilen dürften selbsterklärend sein, ich möchte aber nochmal auf ein paar fokussieren.
Zeilen 26/27: hier wird festgelegt, dass der Payload in MQTT nur aus einem Wert vom Typ float (Kommazahl) besteht. Für Sensoren, die du selber programmierst, ist das der häufigste Fall. Möglicherweise gibt der Sensor hier aber JSON als Payload mit. Die Seite Data Formats Input gibt einen Überblick über die vorhandenen Optionen (das sprengt hier leider den Rahmen alle zu besprechen)
Zeilen 29-32: Topic Parsing ist eine super Funktion, um aus dem MQTT-Topic direkt Tags für die Datenbank abzuleiten. Das Parsing besteht aus mehreren Einträgen, der erste ist immer das Topic, auf das es sich bezieht, hier alle Topics, die drei Ebenen haben und mit sensors/ anfangen. Der Name des Measurements (Datenreihe quasi) wird aus dem dritten Topic-Element abgeleitet ist also entweder temp oder humi. Genauso wird aus dem zweiten Element ein Tag generiert, der in der Datenbank dann "device" heißt und in meinem Beispiel "bedroom" beinhaltet. So kann ich Daten von verschiedenen Sensoren nachher wieder auseinander halten. Achtung: Ich habe es hier "device" genannt, "location" wäre aber vielleicht der bessere Name gewesen. Du kannst mehrere tags gleichzeitig extrahieren.
Beispiel: Angenommen du hast eine große Wohnanlage vernetzt und dein Topic lautet sensors/wohnblockA/etage4/wohnung407/bedroom/temp dann könntest du die tags Zeile wie folgt gestalten: tags = "_/building/floor/unit/room/_"
Nachdem du auf "Save and Test" oder "Save" klickst (ich hatte mal das eine mal das andere angezeigt) sollte eine Testseite aufgehen. Dort bekommst du drei Informationen, deinen API Token für diese Telegraf-Konfiguration, einen Kommandozeilenaufruf zum Testen (darin enthalten die Config-URL) und einen Testbutton.
Zum Testen führen wir Telegraf einmal händisch aus:
export INFLUX_TOKEN=<dein API-Token hier einfügen>
telegraf --config http://localhost:8086/api/v2/telegrafs/<deine Config ID>
Exkurs: Es kann sein, dass du hier eine Fehlermeldung bekommst, dass die Config nicht gefunden wird (oder fehlerhaft ist). Das liegt daran, dass wir nur den Input Bereich der Konfiguration angegeben haben und Influx automatisch den Rest ergänzt hat. Teil davon ist auch die URL zum Pi, die aber in der Config localhost lauten muss. Das ist sehr schade, weil damit die Testseite für uns nicht nutzbar ist. Aber nicht verzagen und einfach mal auf Next geklickt, solltest du den DataCollector als Listenelement auf der Seite sehen. Klicke auf die Überschrift (NICHT auf den Bleistift daneben) um nocheinmal den Editor aufzurufen. Du siehst jetzt, das Influx eine ganze Menge ergänzt hat. Im Abschnitt [[outputs.influxdb_v2]] musst du jetzt den urls Eintrag so anpassen, dass dort http://localhost:8086 statt http://<hostname>:8086/ steht. Wenn telegraf keinen Fehler mehr auf der Kommandozeile meldet, würde ich davon ausgehen, dass es funktioniert.
Falls du keinen Fehler bekommen hast, kannst du auf der Webseite den Test-Button anklicken und siehst sofort, ob telegraf Daten empfängt. ACHTUNG: Falls dein Messintervall >5 Sekunden beträgt, musst du natürlich mindestens eins, besser zwei Intervalle abwarten.
Hat alles geklappt? Prima! Dann lies bei der nächsten Überschrift weiter.
Falls du das hier liest, ist etwas schiefgelaufen. Daher hier ein paar Tipps zur Fehlersuche:
- Überprüfe ganz genau, ob die Topics in der Telegraf Config mit den Topics deiner Sensoren übereinstimmen. "+" ist Platzhalter für eine variable Hierarchie-Ebene, "#" ist Platzhalter für beliebig viele Hierarchie-Ebenen
- Benötigt dein Broker Benutzername und Passwort als Authentifizierung? Dann musst du in deiner Config im Block [[inputs.mqtt_consumer]] noch die beiden Zeilen 21/22
username = "<benutzer>"undpassword = "<passwort>"anpassen und die Kommentarzeichen "#" entfernen. - Wenn du Topic-Parsing benutzt, müssen die Topics alle die gleiche Länge (Anzahl Hierarchieebenen haben), "_" ist hierbei Platzhalter für eine Ebene, die existiert, für das Parsing aber gerade keine Rolle spielt. Im Code oben siehst du, dass alle drei Zeilen exakt 3 Ebenen haben.
- Wenn du eine Fehlermeldung hast, versuche anhand der Fehlermeldung nachzuvollziehen, was schief gelaufen ist. Ach was, Plant?! Was ich sagen will ist, dass es oft Tippfehler sind, die ganz viele andere auch machen und man findet da sehr schnell antworten. Falls du keine Antwort findest, kannst du mir immernoch eine E-Mail oder eine Twitter-DM schicken :)
Telegraf so einrichten, dass es automatisch startet
Als erstes kannst du den manuellen Telegraf Prozess in der Kommandozeile stoppen indem du Strg (bzw. Ctrl) festhältst und einmal C drückst. Das bricht den aktuellen Vordergrundprozess ab.
Wie bereits erwähnt, ist es etwas frickelig die Config in einen selbst startenden Dienst zu integrieren, weil Telegraf nicht unterstützt eine URL im /etc/telegraf/telegraf.d/ Verzeichnis zu hinterlegen. Stattdessen haben wir zwei Möglichkeiten, die bestehende Systemd-Konfiguration anpassen oder eine eigene schreiben. Wenn du nur eine Telegraf-Konfiguration brauchst, ist ersteres einfacher. In dem Fall öffne in einem Texteditor deiner Wahl (mit Root-Rechten) die Datei /etc/systemd/system/multi-target.wants/telegraf.service. In dieser Datei findest du eine Zeile die mit ExecStart= beginnt. Das ist das Programm, das für diesen Service ausgeführt wird. Hier siehst du, dass telegraf aufgerufen wird unter anderem mit dem Parameter --config und --config-directory und nach --config kannst du deine Config-URL von InfluxDB einfügen (und die bestehende damit ersetzen). Nachdem du die Änderung vorgenommen hast, kannst du wie gehabt bei Systemd mit den folgenden Befehlen den Service aktualisieren und neustarten:
systemctl daemon-reload
systemctl restart telegraf
# Falls es nicht startet, findest du mit diesem Befehl mehr Informationen
journalctl -xeu telegraf
Die ausführliche Konfiguration eines Systemd-Services würde hier den Rahmen sprengen, was du aber machen kannst, ist eine angepasste Kopie unter /etc/systemd/system/telegrafmqtt.service abzulegen und anzupassen.
systemctl daemon-reload
systemctl enable telegrafmqtt
systemctl start telegrafmqtt
Eins habe ich noch vergessen. In beiden Fällen musst du dem Service noch dein API-Token mitgeben. Die eine Möglichkeit ist es global für alle zur Verfügung zu stellen (für ein Setup zuhause ok) oder im Systemd-Service direkt anzugeben (Suche dafür nach "Systemd Umgebungsvariable", Beispiel-Erklärung: Ubuntu-Wiki). Ersteres passiert in der Datei /etc/default/telegraf. Wenn du dort die folgende Zeile einfügst, sollte alles funktionieren:
INFLUX_TOKEN=<dein API-Token hier einfügen>
Geschafft, oder?
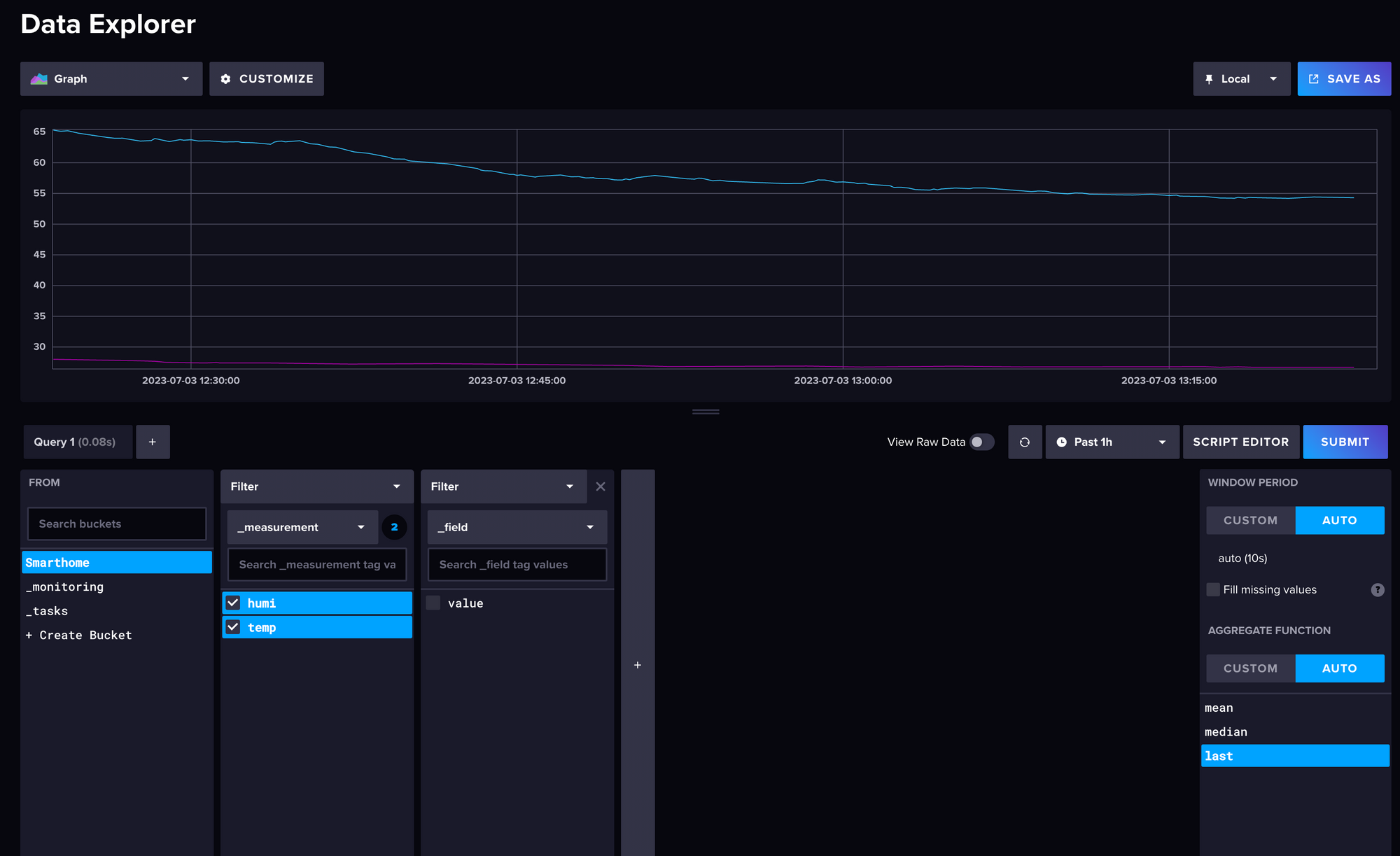
Prinzipiell ja, die Daten sollten jetzt in Messintervall-Schritten in die Datenbank tröpfeln. Aber es wäre relativ unbefriedigend, diesen Blogpost zu beenden, ohne dass du das Ergebnis auch siehst. Deshalb kannst du noch fix zurück auf die InfluxDB Website gehen unter http://10.0.0.5:8086/ und dort auf das Diagramm-Icon klicken um in den "Data Explorer" zu kommen. Die Oberfläche ist relativ komplex, im unteren Bereich (Query 1) links siehst du eine Auflistung deiner Buckets. Klick den Smarthome-Bucket an. Dadurch tauchen rechts daneben Filtermöglichkeiten für deine Daten auf. Dort kannst du anklicken, was du gerne sehen möchtest und dann rechts auf den blauen "Submit"-Button klicken. Jetzt siehst du einen Graph deiner Daten. Auf die Konfiguration dieser Ansicht werde ich nicht in großem Detail eingehen, weil ich dir im nächsten Post gerne Grafana zur Visualisierung vorstellen möchte.
Ich habe mir jetzt 40 Sensoren gekauft und die Wohnung verwanzt, was mache ich als nächstes?
Im besten Fall senden alle diese Sensoren auf dem Topic sensors/... dann musst du einzig die Telegraf-Config anpassen und im Bereich Topic-Parsing mehr Felder und Muster erfassen. Alles andere funktioniert genauso weiter wie vorher. Wenn du nur baugleiche Sensoren kaufst und die auf den gleichen Topics (mit anderem Ort) senden, brauchst du nichtmal etwas umkonfigurieren. Wie bei vielen Technologien, die ich hier im Blog vorgestellt habe, ist die Ersteinrichtung etwas zeitaufwendiger als die spätere Erweiterung.
TL;DR
- InfluxDB Paketquellen hizufügen und influxdb2 installieren
- Telegraf Paketquellen hinzufügen und telegraf installieren
- influxDB unter http://localhost:8086/ bzw. localhost->IP-Adresse vom Pi konfigurieren
a. Benutzername und Passwort wählen
b. Bucket für Daten anlegen
c. Datenquelle telegraf->MQTT consumer wählen
d. telegraf config anpassen und testen - Telegraf config in Systemd-Service eintragen
- Daten in InfluxDB im Data Explorer anschauen
Ausblick
Ich hoffe, dir hat dieser Blogpost einen guten Einstieg in die Speicherung von Sensordaten in deinem Smarthome ermöglicht. Wenn du noch Fragen hast oder weitere Unterstützung benötigst, schreibe mir gerne. Dein Feedback ist ebenfalls sehr willkommen, da es mir hilft, zukünftige Blogposts zu verbessern und auf deine spezifischen Bedürfnisse einzugehen. Ich freue mich auch immer über eine Einsendung, wenn du mit meiner Anleitung etwas Cooles gebaut hast. Viel Spaß beim Auswerten deiner Sensordaten.
Nächstes mal beschäftigen wir uns mit der Datenvisualisierung. Ich werde dir zeigen, wie du mithilfe von Grafana deine gespeicherten Sensordaten ansprechend darstellen kannst, damit du immer den vollen Überblick behältst, was deine Sensoren alles sehen.
Kontakt
E-Mail: info@
Twitter DM: PlantProgrammer
Discord: https://discord.gg/VhgJezz4zA
Unterstützung von plantprogrammer.de
Im letzten Jahr ist mehr denn je klar geworden, dass die Zeit, die ich in diesen Blog investiere sehr stark mit der Zeit für bezahlte Arbeit konkurriert. Daher bitte ich dich, wenn meine Blogposts dir weiterhelfen und du mehr davon sehen möchtest, um deine Unterstützung. Es gibt kostenpflichtige und kostenlose Möglichkeiten meine Arbeit zu unterstützen und alle sind gleichwertig, sodass du das raussuchen kannst, womit du dich wohl fühlst. Ich bin für jede Unterstützung dankbar. Hier eine Übersicht:
Direkte finanzielle Unterstützung:
Indirekte finanzielle Unterstützung (für dich kostenlos):
- Amazon Provision bei Kauf über meinen Referral-Link: https://amzn.to/3OmDC3c (0,5-3% vom Kaufpreis)
- Amazon Provision bei Abschluss von Prime Gratiszeitraum (€3) oder Audible Probe Abo (€10) beide sind für dich kostenlos, wenn du sie sofort nach Abschluss kündigst (bei Audible musst du vorher deinen Gratis-Credit einlösen, das Buch behältst du nach Abbruch des Abos dann)
Ideelle Unterstützung:
- Reichweite. Es muss nicht immer finanzielle Unterstützung sein. Wenn du diesen Blog mit Interessierten Menschen teilst, ist das mindestens genauso viel wert. Dadurch erhöht sich letztlich auch die Chance, dass ich finanzielle Unterstützung durch andere bekomme.
- Feedback. Wenn du Fragen, Anmerkungen, Themenvorschläge und -wünsche äußerst, hilft mir das, höhere Qualität zur Verfügung zu stellen. Dadurch erhöhst du aktiv mit mir die Bereitschaft anderer direkte finanzielle Unterstützung zu bieten.