Vom Datengrab zum Datenschatz: Grafana zur Anzeige von Daten aus InfluxDB


In diesem Teil der Serie geht es vornehmlich um die Anzeige der im letzten Teil gespeicherten Daten und um die Erstellung von Dashboards, um alle relevanten Daten auf einem Blick zusammenzufassen. Der Umfang ist ein grober Überblick, wie üblich kannst du bei Interesse noch viel weiter in die Tiefe gehen.
Lernziele: Grafana Installation und Setup, Flux Query Sprache, Aggregatoren (Mittelwerte, Differenzen, etc.)
Dauer: ~1 Stunde
Nach dem letzten Blogpost gab es den Wunsch nach mehr Bildern, deshalb gibt es in diesem Post auch Abbildungen zu den jeweiligen Seiten und Eingabeformularen. Vielen Dank für das Feedback :)
Voraussetzungen
- Vollständig installierter Raspberry Pi
- Laufende InfluxDB v2 Installation (wie im vorherigen Blogpost)
- Erfasste Messdaten über mindestens 2 Stunden.
- IP-Adresse des Raspberry Pis, in diesem Beispiel immer als 10.0.0.5 angegeben.
Grafana Installation
Ähnlich wie bei der Installation von InfluxDB oder Telegraf im vorherigen Post dieser Serie, musst du zunächst die Paketquelle hinzufügen und dann das grafana Paket installieren. Die Befehle dafür zusammengefasst sind:
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
sudo apt update
sudo apt install grafana
Im Gegensatz zu vielen anderen Linux-Paketen startet Grafana nicht von selbst und du musst den Systemd-Service noch aktivieren und starten
sudo systemctl daemon-reload
sudo systemctl enable grafana-server
sudo systemctl start grafana-server
Sobald Grafana gestartet ist, kannst du per Browser auf Port 3000 auf deinem Pi zugreifen. http://10.0.0.5:3000/ Dort findest du beim ersten Start ein Loginfeld, in das du admin als Benutzername und admin als Passwort eingeben kannst. Du wirst dann auch sofort aufgefordert, das Standardpasswort durch ein neues sichereres zu ersetzen.
Datenquelle erstellen
Um eine neue Datenquelle in Grafana anzulegen, gehst du auf die Startseite z.B. http://10.0.0.5:3000 und wählst im Menü Connections -> Data Sources aus. Wenn es noch keine gibt, wirst du von einem großen Button "Add Data Source" begrüßt, den du anklickst. Falls du schonmal eine Datenquelle angelegt hast, ist der Button kleiner und oben rechts untergebracht. In der Ansicht, die geöffnet wird, klickst du InfluxDB an. In der Regel ist das sehr weit oben gelistet, du kannst aber auch das Suchfeld verwenden.
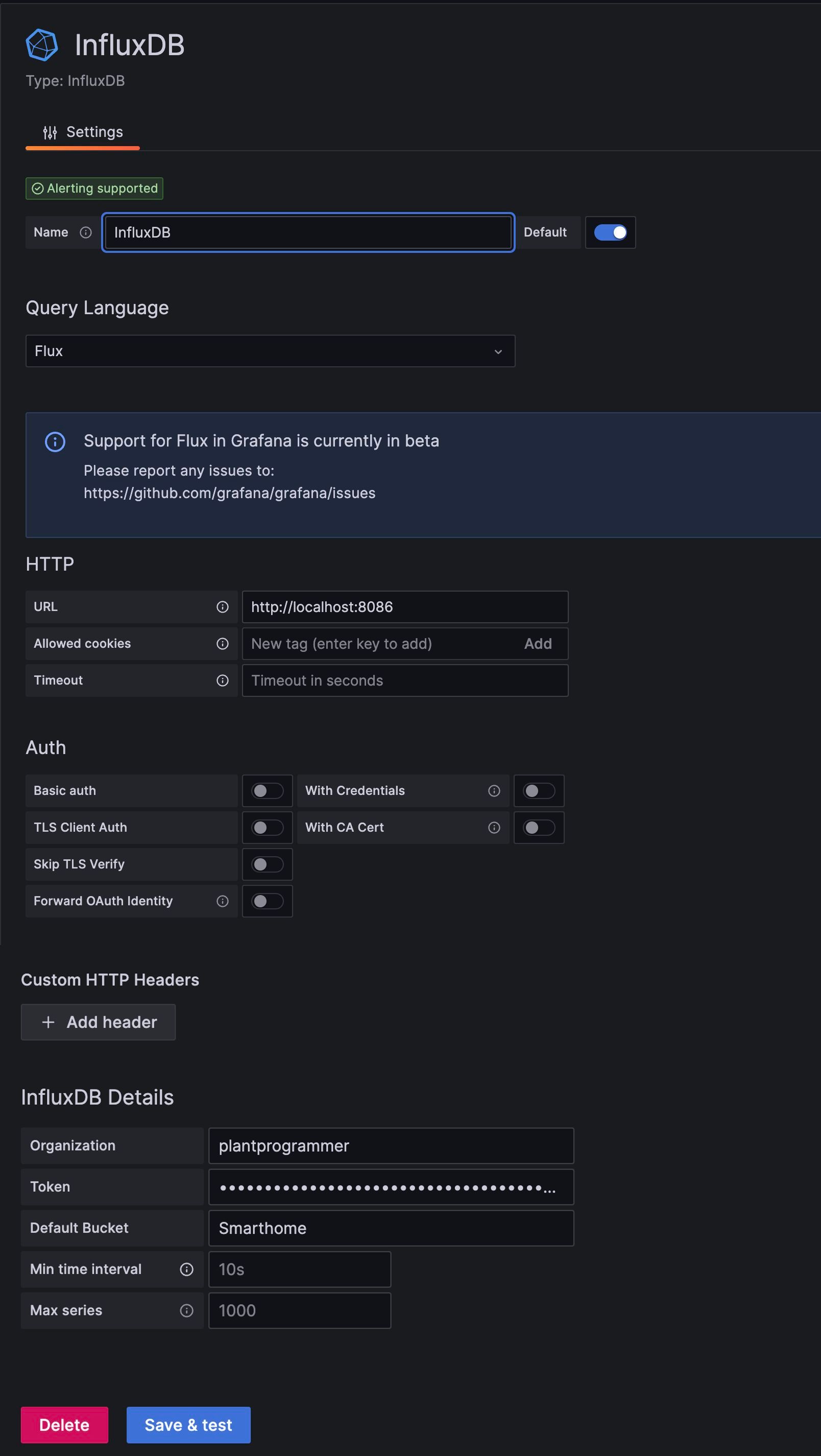
Für die Konfiguration von InfluxDB als Datenquelle ist es extrem wichtig "Query Language" auf Flux umzustellen, sonst sieht die Ansicht bei dir anders aus als bei mir. Ansonsten kannst du einen Namen frei wählen oder den Standard stehen lassen. Unter HTTP musst du die URL eintragen (auch wenn schon der richtige Wert in grau angezeigt wird), in unserem Fall ist beides auf dem Pi installiert, daher ist die URL http://localhost:8086
Den Schalter bei Basic Auth kannst du abschalten und ganz unten die InfluxDB spezifische Konfiguration eintragen, nämlich die in Influx angelegte Organisation (bei mir plantprogrammer), das API-Token, das nach dem Anlegen des InfluxDB Accounts erstellt wurde und einen bucket auf den sich die Datenquelle bezieht, in diesem Fall Smarthome.
Flux Queries
Bevor du dein Grafana-Dashboard erstellen kannst, muss ich dir noch kurz zeigen, wie du Daten aus der DB wieder abfragen kannst. Bisher haben wir die ja nur per telegraf in die DB geschrieben.
Eine Flux Query ist im Prinzip eine Aneinanderreihung von beschreibenden Elementen, um aus der Datenbank eine bestimmte Teilmenge an Daten abzurufen. Diese Queries sind sehr vielseitig und – wenn du sie beherrschst – sehr mächtig. Um den Rahmen dieses Blogposts nicht völlig zu sprengen, gehe ich hier nur auf die allerwichtigsten Komponenten ein.
Variablenname und Bucket:
Eine Query beginnt in der Regel mit der Benennung des Datensatzes, den du gerade abfragen möchtest. In unserem Beispiel könnte das temp oder data oder irgendwas anderes sein. Und als erste Abfrage gibst du an, aus welchem Bucket die Daten stammen sollen. Das sieht dann mit dem Smarthome Bucket zum Beispiel so aus:
temp = from(bucket: "Smarthome")
Zeitfenster:
Da wir es mit zeitbasierten Messdaten zu tun haben, bietet es sich an, ein Zeitfenster anzugeben. Die einfachste Methode den Bereich anzugeben ist mit dem range-Filter. Um diesen an den vorherigen Ausdruck anzuhängen kannst du |> eintippen. Wenn du range einen negativen Startwert mitgibst, dann fragt es alle Daten ab, die zwischen diesem Start und jetzt liegen. Hier sind drei Beispiele (12 Stunden, eine Woche und ein Jahr), wähle einen Bereich davon aus oder schreibe deinene eigenen. Du siehst, es gibt verschiedene Einheiten um den Bereich zu beschreiben, du musst also nicht rechnen, wie viele Stunden ein Jahr hat oder so:
|> range(start: -12h)
|> range(start: -7d)
|> range(start: -1y)
Datenspalten:
Um jetzt bestimmte Datenspalten abzufragen fügen wir noch einen Filter hinzu. Filter sehen zunächst etwas komplizierter aus. Schau dir diesen Filter einmal an, die Erklärung folgt danach:
|> filter(fn: (r) => r._measurement == "temp")
|> filter(fn: ...) sagt InfluxDB, dass die Daten noch gefiltert werden sollen. fn steht für Function und beschreibt eine Funktion, die für jeden Datensatz sagen muss, ob er mit ausgegeben werden soll oder nicht.
das ist genau wofür (r) => ... steht. Für jeden Datensatz kann die rechte Seite des => entweder wahr oder falsch sein. Dabei bedeutet wahr: der Datensatz wird mit ausgegeben und falsch: der Datensatz wird ignoriert.
Schlussendlich wird noch die Bedingung angegeben. Die _measurement Spalte muss gleich temp sein, damit die Daten inkludiert sind. (Zur Erinnerung, die Spalte kann in unserem Fall temp oder humi sein)
Noch ein kleiner Bonus, solltest du vorhaben deinen Stromverbrauch mit smarten Steckdosen zu messen, kannst du dir im Graph auch nur bestimmte Tageszeiten (z.B. 9-17 Uhr) anzeigen lassen, indem du folgenden selbsterklärenden Filter noch hinten anhängst:
|> hourSelection(start: 9, stop: 17)
Zu guter Letzt, müssen wir noch zwei Funktionen anhängen, damit Grafana nachher mit den Daten umgehen kann. Die erste aggregiert die Daten und sorgt dafür, dass es nicht zu viele Datenpunkte gibt und die zweite gibt die Daten dann schlussendlich an Grafana aus
|> aggregateWindow(every: v.windowPeriod, fn: mean)
|> yield(name: "_results")
aggregateWindow bekommt ein Zeitfenster, das in einer Variable v.windowPeriod gespeichert ist. Das ist etwas internes und ich zeige dir später wo du den Wert verändern kannst. fn bezeichnet die Funktion zum aggregieren, wobei hier mean für Mittelwert steht. Eine andere Möglichkeit wäre median. Oder wenn es z.B. um Stromverbrauch geht auch sowas wie sum.
yield bekommt als Parameter nur einen Namen. Ich habe hier den Standardwert _results verwendet, der Name ist aber frei wählbar und es kann mehrere yield geben, sodass man die Daten zu verschiedenen Zeitpunkten der Weiterverarbeitung ausgeben kann.
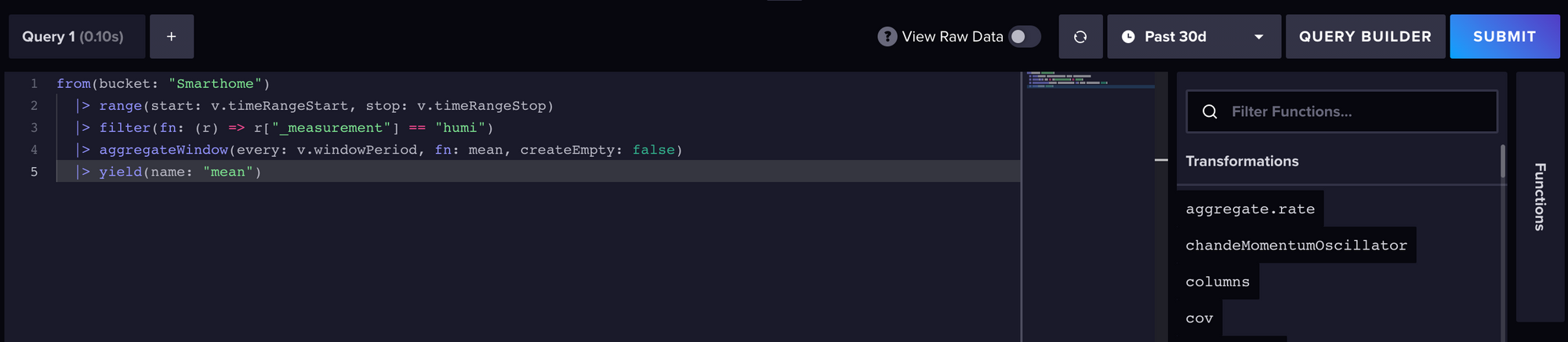
Damit haben wir eine Query, die alle Temperaturdaten eines bestimmten Zeitfensters aus der InfluxDB holen kann:
temp = from(bucket: "Smarthome")
|> range(start: -2d)
|> filter(fn: (r) => r._measurement == "temp")
|> aggregateWindow(every: v.windowPeriod, fn: mean)
|> yield(name: "_results")
Das war ein kurzer Abriss darüber, wie Flux Queries grundsätzlich funktionieren. Es gibt noch ganz viele weitere Funktionen, auf die ich hier nicht eingehe. Viele meiner Leser:innen freuen sich aber über klickbare Oberflächen, die ohne Programmierung auskommen, deshalb folgt hier jetzt der Weg über das Webinterface von InfluxDB
Flux Queries mit InfluxDB erstellen
Wenn du im Browser auf deine InfluxDB Installation unter z.B. http://10.0.0.5:8086 auf Data Explorer gehst, hast du im letzten Post ja schon gelernt, wie du dir eine Query zusammenklicken kannst um Daten anzuzeigen. Wenn du das tust und rechts auf Script Editor klickst, wirst du Flux-Code sehen, der die aktuelle Datenansicht generiert. Start und Stop sind hier mit internen Variablen benannt, die Grafana aber auch versteht. Die Flux-Queries sehen ein bisschen anders aus als im vorherigen Abschnitt, ich werde auf die Details aber nicht weiter eingehen und wollte es dir nur als alternative Möglichkeit aufzeigen.
Grafana-Dashboard erstellen
Um jetzt schlussendlich das Grafana Dashboard zu erstellen, gehst du auf die Grafana-Installation z.B. http://10.0.0.5:3000, im Menü auf Dashboards und dann rechts unter dem New Button auf New Dashboard.
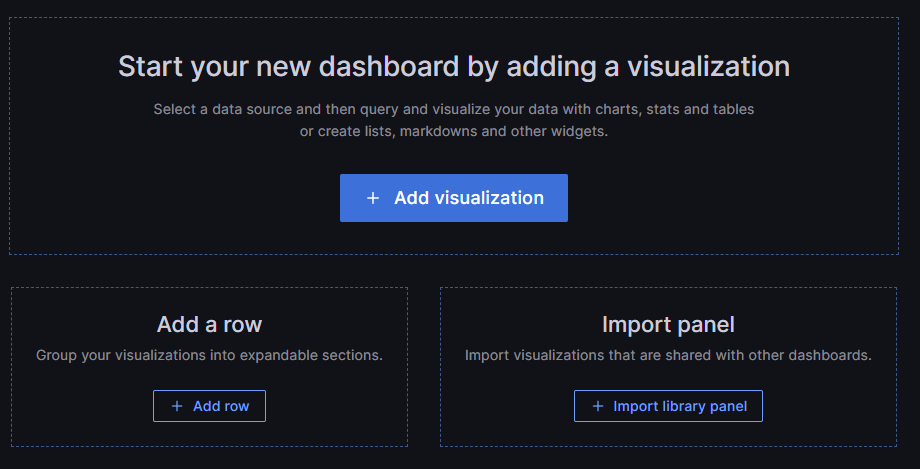
In der nächsten Ansicht kannst du neben neuen Visualisierungen (Datenanzeige) auch Rows (Gruppierung) und vorgefertigte Panel-Vorlagen verwenden. Für den Heimanwendungsbereich reichen voraussichtlich die Visualisierungen aus und deshalb gehe ich auf die anderen Punkte nicht weiter ein, um nicht den Rahmen zu sprengen.
Nach einem Klick auf Add Visualization wirst du aufgefordert eine Datenquelle zu wählen, hier kannst du einfach die InfluxDB Quelle anklicken, die wir oben angelegt haben. Daraufhin landest du in der komplexesten Ansicht dieses Blogposts:
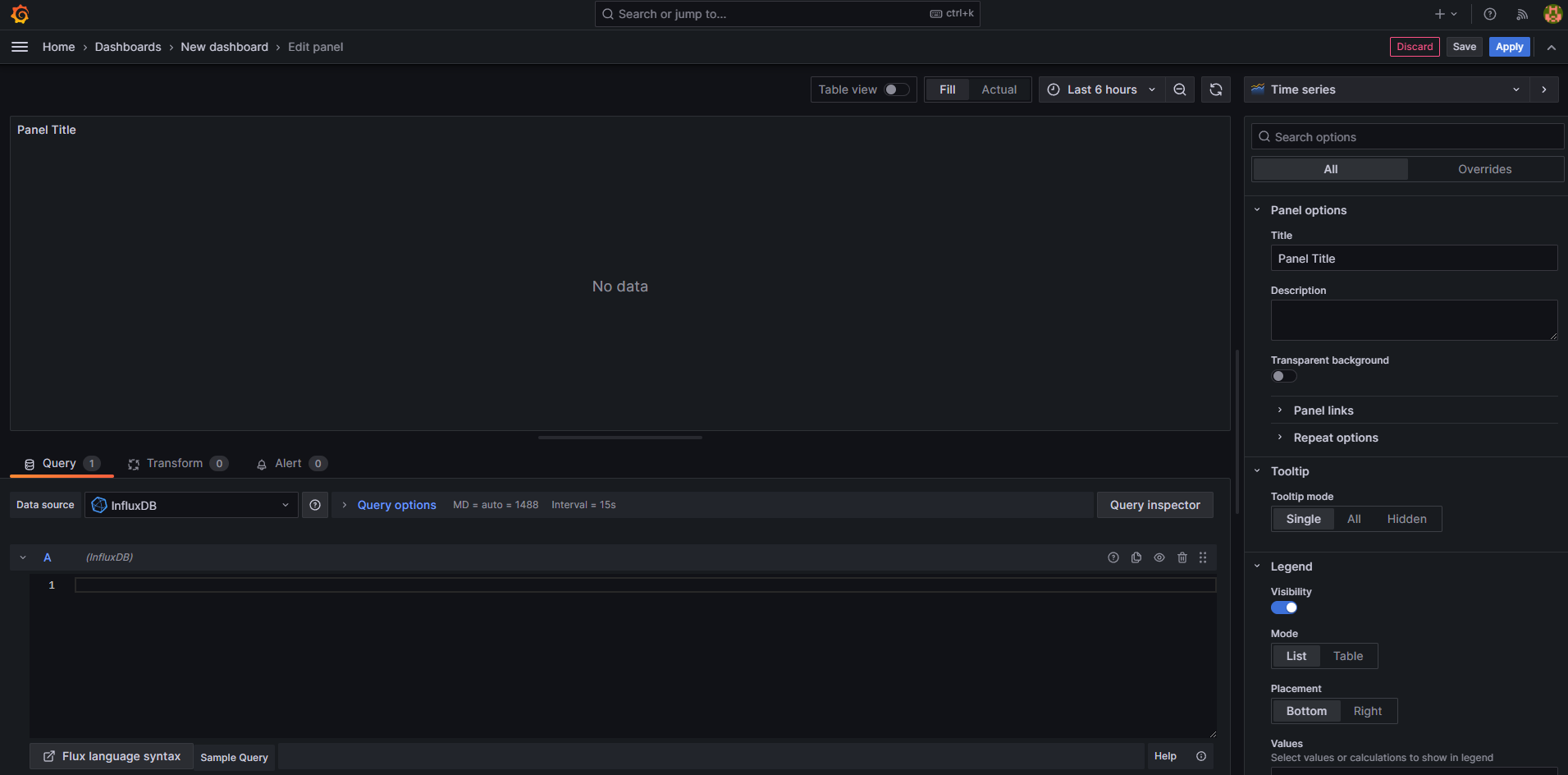
Zentral in der Mitte siehst du eine Vorschau deiner Visualisierung, am Anfang steht dort "no data". Darunter befindet sich der Bereich, in dem du die Datenabfrage (query) konfigurierst. Auf der rechten Seite befindet sich eine Art Inspektor, der dich allerhand Eigenschaften der Visualisierung konfigurieren lässt. Z. B. den Diagrammtitel, aber auch die Achsendimensionen usw. Da gehe ich später noch einmal drauf ein.
Als allererstes und um etwas zu sehen, kopiere die Flux Query aus einem der beiden vorherigen Abschnitte unten in den Query Bereich. Sobald du danach irgendwo anders hinklickst (z.B. auf das Diagramm) wird die Query ausgewertet und möglicherweise siehst du jetzt schon deine Daten. Falls nicht, kannst du rechts oberhalb der Diagrammfläche oder im Fluxcode den Zeitraum noch einmal variieren.
Im oberen Bereich des Code-Fensters siehst du die Datenquelle (InfluxDB) hier kannst du nochmal die Query-Options einstellen. Da steht im Prinzip in welchen Zeitabschnitten (Interval bzw. Min-Interval) und wie viele Datenpunkte du maximal du aus der DB holen möchtest zur Anzeige.
Wenn du schon zufrieden bist, kannst du jetzt oben rechts auf apply klicken und landest in deinem ersten Dashboard mit Anzeige der Temperatur. Wann immer du weitere Grafiken hinzufügen möchtest, nutzt du den Button Add->Visualization im Dashboard. Außerdem kannst du an jedem Diagramm auf das Schaschlik-Menü auf Edit klicken um wieder in den Diagramm-Editor zu kommen.
Diagramm-Eigenschaften
Das rechte Menü ist sehr ergiebig um verschiedenste Informationen und visuelle Effekte im Diagramm unterzubringen. Am besten ist, du spielst damit herum und schaust was passiert. Wenn du ein strategischeres Vorgehen bevorzugst, gebe ich dir hier aber noch die für mich wichtigsten Punkte mit.
Title: Den Diagrammtitel kannst du in diesem Feld anpassen.
Legend: Hier kannst du die Legende ein- und ausschalten, aber was noch viel cooler ist, im Feld Values kannst du angeben, welche Kennzahlen in der Legende noch angezeigt werden sollen. Zum Beispiel Min- und Max-Wert oder die Differenz zwischen dem ersten und letzten Wert aus dem Anzeigebereich (zum einfacheren Vergleich von Änderungen im Zeitverlauf).
Display Name: Unter Standard Options kannst du noch den Anzeigenamen des Datensatzes in der Legende ändern, damit da nicht sowas kryptisches autogeneriertes steht sondern zum Beispiel Temperatur. Etwas darüber kannst du sogar die Maßeinheit (Unit) auf Temperature->Celsius setzen.
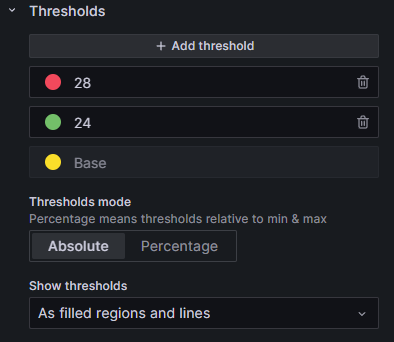
Thresholds: Ich mag diesen Abschnitt noch sehr gerne, weil er dir erlaubt kritische Bereiche im Diagramm einzufärben: Zum Beispiel >28°C rot <24°C gelb dazwischen grün. Dafür setzt du den ersten Threshold auf 28 und färbst in rot ein, den zweiten auf 24 und färbst ihn grün ein und den base threshold färbst du gelb ein. Base ist immer der unterste, weswegen man quasi immer die Farbe bis zur nächsten Schwelle von dem Wert nach oben zum nächsten angibt. Der oberste geht dann Richtung unendlich und der Base Wert Richtung minus unendlich.
Durchatmen, Wiederholen & Mehr Datenreihen
Ab hier ist der Prozess im Prinzip immer wieder der gleiche um neue Diagramme hinzuzufügen. Deshalb und wegen der fortgeschrittenen Post-Länge, überlasse ich den Rest vorerst dir. Zwei Anmerkungen sind aber vielleicht noch wichtig.
1. Du kannst die Daten gruppieren (in meinen Beispielen geht das nicht, weil ich nur ein Messdevice laufen hatte um diese Anleitung zu schreiben). Wenn du zum Besipiel 5 Temperatursensoren in der Wohnung verteilt hast und in Influx den Raum in einem Feld namens room mit erfasst, kannst du mit dem folgenden Filter die einzelnen Räume als einzelne Linien im selben Diagramm anzeigen lassen:
|> group(columns: ["room"])
columns steht hierbei dann für die DB Spalte/n (wenn du nach mehreren gruppierst z.B. ["room", "apartment"], ist jede vorkommende Kombination aus allen Spalten eine Gruppe)
2. Wenn du mehr Datenreihen in ein Diagramm packen möchtest, kannst du ganz unten auf der Seite +Query anklicken und eine weitere komplett unabhängige Query verwenden, die aber ins gleiche Diagramm gezeichnet wird.
Fazit: Daten visualisieren mit Grafana
Mit diesem Teil der Serie hast du gelernt, wie du die gespeicherten Daten aus dem vorherigen Blogpost in Grafana visualisieren und übersichtliche Dashboards erstellen kannst. Wir haben uns Flux Queries genauer angesehen, um gezielt Daten aus der InfluxDB abzufragen und sie in Grafana ansprechend darzustellen. Außerdem hast du einen Überblick über die wichtigsten Funktionen und Optionen für die Konfiguration der Visualisierungen kennengelernt.
Für meinen Geschmack ist dieser Blogpost etwas zu kurz geraten, ich habe mich dennoch entschieden, ihn so zu veröffentlichen und stattdessen den nächsten etwas ausführlicher zu gestalten, weil ich auch gerne ein bisschen auf die mathematischen Hintergründe der Datenverarbeitung eingehen möchte. Daher wird der nächste Teil auch voraussichtlich nicht vor Ende August 23 erscheinen. Falls du noch konkrete Informationen suchst oder Fragen hast, die diesen Teil hier betreffen, schreib mir gerne. Ich ergänze dann beantwortete Fragen hier im Post.
Kontakt
E-Mail: info@
Twitter DM: PlantProgrammer
Discord: https://discord.gg/VhgJezz4zA
Unterstützung von plantprogrammer.de
Im letzten Jahr ist mehr denn je klar geworden, dass die Zeit, die ich in diesen Blog investiere sehr stark mit der Zeit für bezahlte Arbeit konkurriert. Daher bitte ich dich, wenn meine Blogposts dir weiterhelfen und du mehr davon sehen möchtest, um deine Unterstützung. Es gibt kostenpflichtige und kostenlose Möglichkeiten meine Arbeit zu unterstützen und alle sind gleichwertig, sodass du das raussuchen kannst, womit du dich wohl fühlst. Ich bin für jede Unterstützung dankbar. Hier eine Übersicht:
Direkte finanzielle Unterstützung:
Indirekte finanzielle Unterstützung (für dich kostenlos):
- Amazon Provision bei Kauf über meinen Referral-Link: https://amzn.to/3OmDC3c (0,5-3% vom Kaufpreis)
- Amazon Provision bei Abschluss von Prime Gratiszeitraum (€3) oder Audible Probe Abo (€10) beide sind für dich kostenlos, wenn du sie sofort nach Abschluss kündigst (bei Audible musst du vorher deinen Gratis-Credit einlösen, das Buch behältst du nach Abbruch des Abos dann)
Ideelle Unterstützung:
- Reichweite. Es muss nicht immer finanzielle Unterstützung sein. Wenn du diesen Blog mit Interessierten Menschen teilst, ist das mindestens genauso viel wert. Dadurch erhöht sich letztlich auch die Chance, dass ich finanzielle Unterstützung durch andere bekomme.
- Feedback. Wenn du Fragen, Anmerkungen, Themenvorschläge und -wünsche äußerst, hilft mir das, höhere Qualität zur Verfügung zu stellen. Dadurch erhöhst du aktiv mit mir die Bereitschaft anderer direkte finanzielle Unterstützung zu bieten.